
Software-defined storage (SDS) solutions have come a long way in recent times and branched into areas that were previously thought impossible.
IT best practice has always been about eliminating single points of failure. Back in the late 20th century, companies ran their software, applications and services on bare-metal servers which only had enough CPU to run one application at a time, and had limited scalability options.
Applications themselves were constrained by the size of the server in terms of CPU, performance, available memory, and the number of disk slots. So in order to eliminate single points of failure, the idea was to have more than one of each critical component. In order to prevent downtime, power supplies were doubled, network connections were made to redundant switches, single applications were allocated their own dedicated server, and overall a lot of power and time was wasted in maintaining and running these systems, just to keep the lights on.
But with the advent of server virtualization, the landscape completely changed…
What is server virtualization?
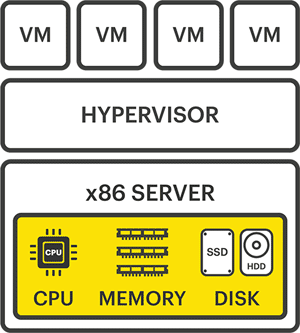 Server virtualization has its origins in the 1960s when it was first pioneered by IBM, though it wasn’t used in the way it’s known today until the late 1990s and early 2000s.
Server virtualization has its origins in the 1960s when it was first pioneered by IBM, though it wasn’t used in the way it’s known today until the late 1990s and early 2000s.
It was at this point when the discovery of running multiple virtual OSE’s (virtual operating system environments) or VMs (virtual machines) on a single x86 server was made. Now, proper redundancy could be created and at an affordable level. Physical servers could now run multiple-core CPUs, dividing up resources, and portioning them up amongst a number of virtual machines on a single hypervisor.
These virtual OSEs or VMs were able to migrate from one to the other, based on just a few basic requirements. These included the same hypervisor environment, some sort of orchestration tool (e.g. vCenter), a network connection, and the subject of our analysis, shared storage.
Enabling a single volume of data to be accessed by multiple hypervisors meant an entire physical server could fail, and the VMs would then migrate to another, all because their location — the storage — remained the same. These advancements allowed organizations to achieve an incredible increase in power and resource efficiency, significantly reduce their hardware footprints, and embrace the Storage Area Network (SAN) — the foundation that nearly all datacenters and distributed computing platforms are built on today.
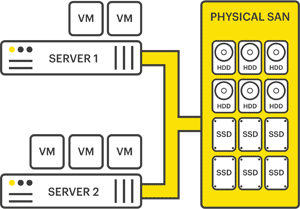 A single physical SAN, accessed via iSCSI or fibre channel by a cluster of hypervisor servers, would have multiple inbound connections, multiple power supplies, and multiple disks in a redundant array (RAID). But there was still a single box controlling it all, and should that box fail, the entire system would go down with it. Thus, despite the advancements in server virtualization, the single point of failure was not eliminated, just moved.
A single physical SAN, accessed via iSCSI or fibre channel by a cluster of hypervisor servers, would have multiple inbound connections, multiple power supplies, and multiple disks in a redundant array (RAID). But there was still a single box controlling it all, and should that box fail, the entire system would go down with it. Thus, despite the advancements in server virtualization, the single point of failure was not eliminated, just moved.
For datacenter environments, a storage array failure would be less than ideal. But for SMEs and distributed enterprises operating at the edge, and IT staff being hours, days or even weeks away from each site, equipment going down could spell complete disaster. To reduce this risk, companies began duplicating the storage infrastructure with complicated strategies to replicate the data between them. Though this helped avoid a complete shutdown when a storage array failed, it also created huge increases in IT hardware footprint, complexity, and cost.
This was all well and good if the organization had the budget for these systems, the network infrastructure between sites was capable of supporting mass amounts of data, and the IT staff were wise enough to think outside the box and embrace the changes as they came. For the rest, shared storage was just too high a price to jump into. A more affordable alternative was needed.
Enter, software-defined storage solutions and virtual SANs
For a more detailed explanation of software-defined storage, check out our beginners guide.
 Complicated as it may sound, software-defined storage solutions just take the initial cues of server virtualization to the next level — virtualizing the SAN itself. No need for an expensive, physical storage appliance: just hardware with sufficient processor, memory, and storage resources to accommodate and execute multiple applications. An additional user benefit of software-defined storage solutions is the traditionally associated cost of entry is significantly reduced, too.
Complicated as it may sound, software-defined storage solutions just take the initial cues of server virtualization to the next level — virtualizing the SAN itself. No need for an expensive, physical storage appliance: just hardware with sufficient processor, memory, and storage resources to accommodate and execute multiple applications. An additional user benefit of software-defined storage solutions is the traditionally associated cost of entry is significantly reduced, too.
A virtual SAN (vSAN) solution is a software-defined storage solution, and so comparing a virtual SAN to software-defined storage is largely pointless. Virtual SANs run as virtual machines, kernel modules or applications on industry standard operating systems or hypervisors, using commodity x86 servers and internal server or directly attached storage. They provide many of the storage features found in dedicated storage arrays, including synchronous mirroring, enabling an exact copy of the data to be replicated on other virtual SAN nodes, providing the all-important highly available shared storage necessary to use the advanced hypervisor features.
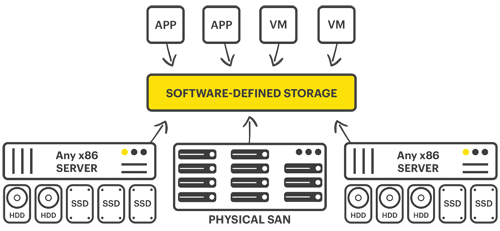 As software-defined storage developed, vendors in the virtual SAN space tried to redefine the entire enterprise IT environment, offering all-in-one solutions with a small footprint and which remove the single points of failure. However, these all-in-one solutions are still expensive systems, designed as a replacement for the big datacenter. Small organizations with a single Windows Small Business Server (SBS) for example, are totally unsuited to such solutions. The next step-up would be Nutanix, VxRail, or vSAN; just a few of the players in the hyperconvergence space. Yet all of these require a total commitment to that platform, both in basic hardware requirements and licensing, and are often an over-provisioned and over-priced solution for small businesses or locations that don’t require datacenter-class systems.
As software-defined storage developed, vendors in the virtual SAN space tried to redefine the entire enterprise IT environment, offering all-in-one solutions with a small footprint and which remove the single points of failure. However, these all-in-one solutions are still expensive systems, designed as a replacement for the big datacenter. Small organizations with a single Windows Small Business Server (SBS) for example, are totally unsuited to such solutions. The next step-up would be Nutanix, VxRail, or vSAN; just a few of the players in the hyperconvergence space. Yet all of these require a total commitment to that platform, both in basic hardware requirements and licensing, and are often an over-provisioned and over-priced solution for small businesses or locations that don’t require datacenter-class systems.
StorMagic SvSAN: a software-defined storage solution
StorMagic takes a different approach and doesn’t aim to take over or force its users to be any particular type or size. We don’t provide an additional hypervisor for staff to learn, or require users to buy a specific type of storage or server hardware. We take the key problem of eliminating downtime, and extend that to within reach of any organization, allowing shared storage, and utilizing hardware they can afford. While it may seem this is purely a low-cost, entry-level product, the flexibility it offers allows systems to be architected with less hardware, less running costs, and less licensing overhead. It is simple, enabling organization’s to do exactly what they need to: keep their applications and data online, at all times, regardless of a component failure.
StorMagic SvSAN is a small, lightweight software-defined storage system, capable of running on incredibly low-cost commodity x86 servers, from any vendor. Customers can use VMware, Hyper-V, or KVM hypervisors for server virtualization. The overhead required for mirroring storage across two servers is minimal, far lower than that of a full hyperconverged infrastructure platform, and with our proven multi-site, edge-focused approach to managing your estate as you always have, it allows progression with regression. Functionality is increased without the need to over-spec the hardware, and simplicity assists in deployment and management that is second to none, on any platform, at any time.
Put as simply as possible, StorMagic gives you access to enterprise software-defined storage without the enterprise price tag. Try SvSAN with a no-obligation free trial, and start thinking about how less can actually be more for your organization.


