
IoT is on the Rise…
The Internet of Things (IoT) is a hot topic right now, experiencing dramatic growth, driven by the increased use of connected devices, or endpoints. These devices vary from sensors, actuators, and valves in factories, to home automation control systems (Nest, Apple HomeKit, Philips Hue), wearable fitness trackers (Fitbit, Garmin), smartphones, and even traffic and transport sensors in smart cities. What they all have in common is what they do – generate, monitor, and analyze vast swaths of data to provide instant real-time feedback, and where they’re found – typically at the network edge.
To put this into perspective, IDC estimates a staggering 55.7 billion IoT devices will be connected by 2025, generating around 80 zettabytes of data1. According to Gartner research, this massive market will represent a 33 billion dollar opportunity in 2025 with a CAGR increase of 34% from 20202.
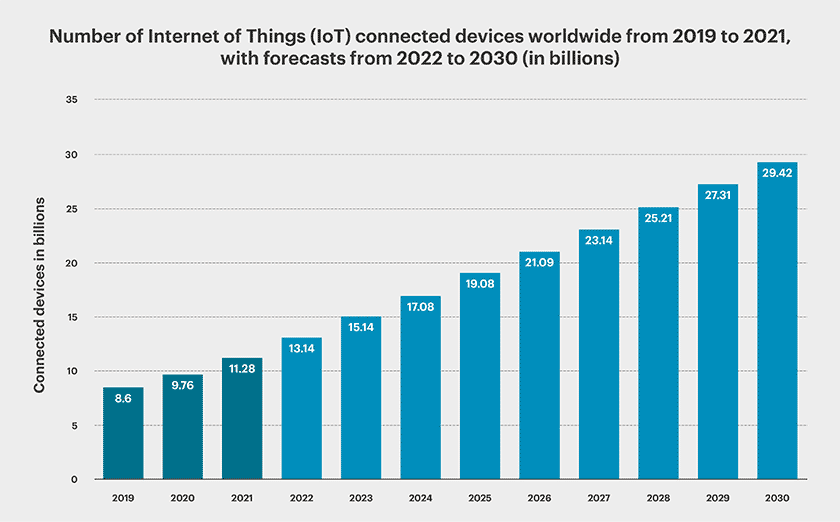
IoT devices are predicted to create an explosion in the volume of data produced and put increasing pressure on vendors to develop solutions that will allow for it all to be stored and processed effectively. For distributed remote IT environments outside the datacenter (also known as the “edge”) this is expected to be hundreds of zettabytes worldwide, with all of this data needing to be aggregated, processed, stored, and managed.
How Does Edge Computing Help IoT?
Edge IoT devices and sensors constantly generate huge amounts of data. As such, traditional centralized or cloud computing models cannot meet processing and analysis requirements in a timely manner. Often, a rapid response is required, like shutting off or opening a valve in response to a pressure or temperature reading in a chemical manufacturing factory.
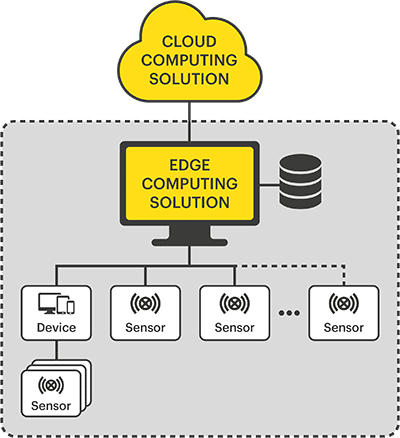 These traditional models rely on moving all data from the edge, where the data is created, to a centralized location for processing, making them vulnerable to network latency which some applications or processes may not be able to tolerate. Additionally, data generated from thousands of devices can quickly consume all available network bandwidth capacity.
These traditional models rely on moving all data from the edge, where the data is created, to a centralized location for processing, making them vulnerable to network latency which some applications or processes may not be able to tolerate. Additionally, data generated from thousands of devices can quickly consume all available network bandwidth capacity.
Effectively addressing latency and bandwidth requirements, all of which are lacking in traditional computing models, are some of the main advantages of edge computing for IoT over cloud computing. These IoT edge solutions are able to analyze the data close to where it is generated and collected, vastly reducing the distance it has to travel to be processed, and the volume having to be transferred over the wide-area network. In addition, IoT edge computing prevents organizations from having to spend considerable sums on high-capacity network links, instead leaving them with the extra budget to spend on localized improvements that cost significantly less.
The Advantages of an IoT Edge Computing Model:
Reduce Network Bandwidth
As previously mentioned, IoT devices and sensors generate large amounts of data. For example, a typical offshore oil platform generates between 1 TB and 2 TB of data per day4.
Much of this data is transient in nature, often only useful for a short period after being generated. Therefore, it is not practical to transfer all the data from edge IoT devices to the cloud. Instead, it is better to analyze or “mine” the data at the edge, only sending the “nuggets” of refined data back to the centralized storage location for further processing. Using this approach significantly reduces the amount of information needing to traverse the network.
Minimize Network Latency
For time-critical applications that require real-time decision-making, milliseconds matter, spelling the difference between normal operations and failure. Transferring data to a cloud or central datacenter for processing and then waiting for the response adds unnecessary network latency. This is even more significant when the network latency from the edge site to the central datastore is high, such as over a satellite link. Therefore, it is best to analyze the data close to where it was generated, minimizing the time added by network latency.
Process Data in the Most Appropriate Place
Choosing the location to process or analyze data depends on how fast a decision needs to be made and how transient the data is. For environments that have large amounts of transient data, but are time-sensitive and require immediate feedback, the data processing should be performed at the edge, closer to the devices generating and acting on the data. However, if the data is required for historical analysis for instance, and needs to be kept for longer periods of time for regulatory purposes, then it may be better to transfer the refined data to a central datastore for offline, post-processing.
| Edge | Central Datastore (Data center, Cloud) |
|
| Response time |
Milliseconds / subsecond | Seconds to minutes |
| Longevity | Transient (seconds, minutes, hours) | Longer term (days, weeks, months or years depending on application / data) |
| Geographical coverage |
Very local (single site) | All sites (aggregate all data) |
Deliver Edge Computing High Availability
For some IoT locations, such as oil rigs, solar farms, or remote processing plants, network connectivity may not have sufficient bandwidth, have high latencies, be unreliable (high error rates), and in some cases may not even exist. For these locations, using traditional centralized or cloud computing solutions is not an option.
The only alternative available to these locations would be to use an edge computing solution to ensure the smooth running of the service. For very remote locations it would be prudent to ensure that any edge computing solution is highly available or better fault tolerant to guarantee all services and critical data are protected and available in the event of a component failure. This is especially true for sites that may have minimal access to readily available spare parts and IT assistance.
Reduce Cost
Another factor to consider is the cost of the solution. Using a cloud model may have the benefits of centralizing all the data and relatively cheap compute costs. However, this would require additional network infrastructure to transfer all the data. This, coupled with the huge amounts of data that need to be stored within the cloud, means costs add up very quickly.
On the other hand, using an edge model would allow data to be stored and processed locally, only sending the important information back to a central location for further analysis. This not only dramatically reduces network costs, but also reduces the amount of cloud storage required.
The Ideal IoT Edge Computing Solution
It’s clear therefore, that a fully centralized solution may not fit within all IoT environments due to network latencies, bandwidth, and/or cost. An alternate approach would be to use a hybrid architecture which factors in a number of considerations. An edge computing solution is used to process and store the majority of the raw edge IoT data close to where it was generated. As only the important or refined data is transmitted to the datacenter for further analysis and long-term retention, it ensures timely responses to events.
To achieve this, edge computing IoT solutions must have the following:
- Small Footprint: The solution should have a small footprint in terms of space, power, and cooling requirements, as typically there is limited space for IT equipment at each location.
- Robust: IoT devices are often deployed in harsh environments (i.e. oil rigs, manufacturing plants, etc). Ideal IoT edge solutions should be designed with components that are resilient (for example, fanless servers for dusty/dirty environments or the use of SSDs that are more resilient to excessive vibration, shock, pressure, or extreme temperature changes).
- Highly Available: The solution should be resilient to withstand single-component failures, to ensure that operations are not interrupted.
- Low Cost: The solution needs to be low cost for both initial acquisition and ongoing operations. This includes power and cooling, which can be significant as the number of locations requiring edge computing resources increases.
- Simple: The solution should have a simple, repeatable design that makes it easy to deploy and maintain.
- Easy to Manage: The solution should be capable of being monitored and managed from a central support location.
StorMagic SvSAN is an ideal IoT edge computing solution built for harsh environments. Designed specifically for distributed sites it’s perfectly adapted at handling the realities of poor network reliability often found in remote areas. Starting with just two servers, SvSAN has a lightweight footprint and creates a highly available, virtual SAN using the server’s internal storage, that is both cost-effective and easy to manage. Learn more about SvSAN, in our SvSAN Overview or in our Product Datasheet.


