
Did you know that most disasters are localized to a specific room, building, or campus? Similarly, the majority of maintenance and repairs are completed in a single location too.
These more frequent events often create significant disruption for IT operations. Luckily, this disruption can be reduced or eliminated through the use of stretch clusters. Join us for an in-depth navigation into the complexities of deploying stretch clusters. Here we cover the benefits and limitations of using stretch clusters and the key practices that ensure their seamless deployment, high availability, and disaster recovery.
What are stretch clusters?
Stretched clusters, also referred to as stretch clusters or metro clusters, represent a cluster configuration that spreads virtualized infrastructure across distinct geographic locations (usually two sites). Designed to enhance availability and facilitate disaster recovery, this technology is most commonly found in places like campuses, hospitals, and other locations where the distance between datacenters is under 1000km.
In a stretched cluster setup, each cluster node is active, and in the event of a cluster node failure at one site, storage resources from the other sites are utilized. This arrangement allows for planned maintenance activities and mitigates the impact of unforeseen disasters like fires and hurricanes, ensuring uninterrupted cluster operation.
What are the benefits of stretch clusters?
For organizations dependent on high availability and redundancy from their infrastructure, like those operating in healthcare, transport, and manufacturing, stretch clusters can offer an ideal solution. Data mishaps, power glitches, cooling problems, and natural disasters are all very real threats to the integrity of data.
To ensure business continuity and resilience, stretch clusters maintain critical data access to minimize operational disruptions. Additionally, they optimize hardware utilization across multiple locations, offering a cost-effective alternative to traditional setups using legacy hardware.
What are the limitations of stretch clusters?
When deploying a stretch cluster solution, bandwidth and round trip time (RTT), or latency, need to be considered. A frequent struggle for many solutions on the market is data, in particular, too much data being sent at once. This restricts the amount of latency that the solution can tolerate and forces the user to create expensive, high-bandwidth networks.
All too often, when rough patches in network performance occur, users mistakenly chalk it up to congestion and try to fix the problem by boosting the network bandwidth. But, just like opening up more lanes on a highway during rush hour, this only solves the problem when there’s actually congestion in the network. Like having a max speed limit of 5mph per lane, it won’t help if the travel speed of the data in question is simply slow.
For this issue, lowering network latency, or round trip time (RTT) is key. But as those who have tried in the past, this can be a tricky beast as it’s typically outside the user’s control forcing them to look at addressing a range of factors including:
- Decoding and re-encoding the data.
- Fixing network bottlenecks caused by routers and switches and propagation delays (caused by the time it takes data to travel across copper or fiber networks).
- And even assessing each application’s tolerance to latency.
In short, understanding the challenges and limitations of each stretch cluster on a case-by-case basis is necessary to ensure it performs as needed.
What are the best practices for deploying stretch clusters?
There are a few practices to stick to if the smooth deployment and operation of a stretch cluster are to be ensured. To start, all nodes should be the same make and model to ensure compatibility across the cluster. Not only can this be useful for general maintenance, behavior, deployment, and performance, but it also assists with the troubleshooting processes. Additionally, node uniformity can help maintain data consistency where the data is replicated synchronously between geographically separate locations.
It is worth noting that there are some exceptions to this, so it’s important to check with your vendor before purchasing or rolling out any architecture.
Using a minimum of two nodes in a cluster, ideally in different geographical locations can also help prevent unplanned downtime and service interruptions should a local or regional disaster strike. Additionally, keeping the nodes within around 1,000 km of each other, while using an architecture (like an edge computing solution) can help create an environment with low latency and protect against performance degradation and unpredictable behavior. The exact maximum distance will, however, be dependent on the vendor’s system requirements.
Last and most importantly, deploying a witness to act as a tie-breaker in case of a network partition between two sites can help maintain data consistency and ensure the operations can continue as normal should one site become isolated from the other. Depending on the solution chosen, this could be as many as one witness per cluster, or as few as one witness per one thousand clusters.
Increasing resiliency using stretched clusters with StorMagic SvSAN
With the ability to be deployed in a single location or up to 1,000 km apart, StorMagic offers its users flexibility and peace of mind.
Whether deployment takes place in the same rack, room or building, or at opposite ends of a metro area, the solution protects precious data against localized disruption like a pulled power cable, and natural disasters like a hurricane or tornado.
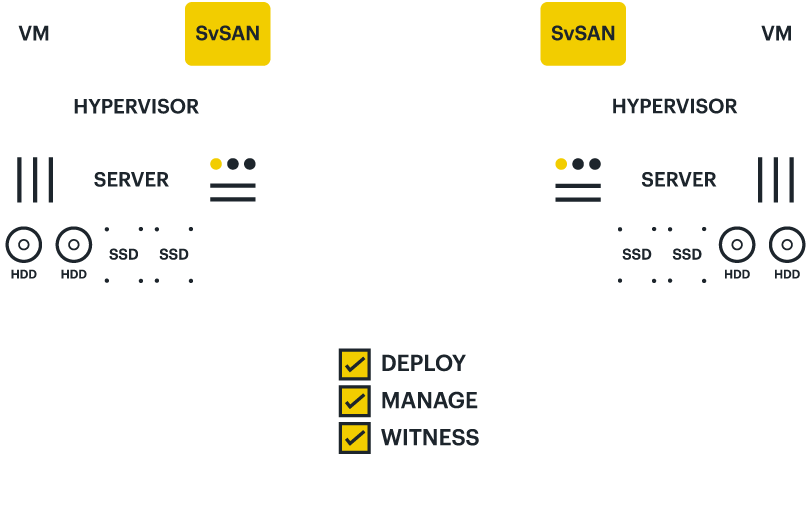
Through the use of synchronous mirroring and a remote witness node, SvSAN creates a highly available environment, such that if one side of the cluster suffers an unexpected outage, all applications running at both locations keep on running. When service is restored, the datastores are automatically rebuilt and HA is restored within minutes.
SvSAN stretch clusters continue to perform effectively with high latencies and over long distances, making them a resilient option for data storage.
What’s more, our flexible, lightweight architecture works on any mix of x86 server and hypervisor and has constant response times and IOPS with up to 10ms of latency. Check out our Creating Stretch Clusters with StorMagic SvSAN white paper for a deeper dive into stretch clusters, and for details on how we tested this.
To learn more about SvSAN, visit our product page:
Or to find out how we can meet your specific requirements, you can contact the team at [email protected]


