
With the advent of mobile connectivity, bring-your-own-devices, working from home, and this unilateral shift from on-premises to the cloud, the very way we consume and work with our data on a day-to-day basis has changed and is continually shifting.
We’re used to these buzzwords being thrown at us from all angles, none more so lately than edge computing. But what is the definition of edge computing? And most importantly, why should you care about it?
What is edge computing?
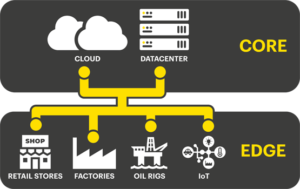
A distributed IT architecture, edge computing is a technology that allows client data to be processed at the network edge, as close to the source where the data is generated as possible. Leveraging this model, users are able to avoid the latency issues associated with transmitting raw data to the datacenter, avoiding lags in performance or even delays (which could prove fatal in certain industries). These devices then send actionable answers like real-time business insights and equipment maintenance predictions back to the main datacenter for review and human intervention.
Today the majority of industries operate at the edge including remote patient monitoring equipment in hospitals and healthcare, IoT devices in factories, sensors in autonomous vehicles like cars and trains, and even retail stores and smart cities.
For more detail on the definition of edge computing, refer to our Beginners Guide.
Edge computing: An origins story
To fully understand the need for edge computing as a technology, we’ll need to go back to its origins, an era in recent history where the “server” was a physical machine that required skilled and experienced engineers to keep it running. Terminals would be directly connected, sometimes even by some proprietary interface like a serial cable, and interruptions to the service would often affect everyone at once.
Modernizing this process meant removing the proprietary and standardizing interfaces. Generally, we point to “Microsoft Windows” as a primary driver of this (among other tools) as it fundamentally changed the way computers were used and interacted with each other, and reduced training requirements to give application owners and developers a common platform to work on – making their work less bespoke and more useful to a greater audience.
Next came modernizing the infrastructure itself. Data could now be held in commodity servers, running off-the-shelf software. Standards were set up; parts became cheaper; skills increased; and innovation thrived. In the world of storage, standardization happened around fiber-channel connectivity, which allowed storage to move outside the server and be housed in enterprise-class, shared storage solutions like SAN and NAS.
At the tail end of this chapter was the introduction of virtualization, further modularizing services and provisioning, and in turn reducing the hardware required to manage data and workloads in a distributed way. One of the key requirements of server virtualization was external shared storage – typically a physical SAN. Using this, all the virtualized servers in a cluster could access the same storage. Initially, the only way to implement a cluster of virtualized servers, these traditional strategies started to be replaced by big ideas and complexity. Enter: the cloud.
The cloud, or as it’s commonly thought of, the big datacenter in the sky that you can’t see or touch, is simply someone else’s datacenter. Rented on more professionally managed hardware, it removed all the pain of managing a datacenter yourself, creating a much more efficient process. Those running the cloud could scale their infrastructure up efficiently and cost-effectively, offering services to those who would not have been able to afford to enter this space before now.
So, is having a cloud strategy really the Golden Ticket to a pain-free and easy-to-manage IT portfolio?
Let’s not forget that the IT landscape has changed significantly over the years. While the common office worker doesn’t know, understand, or care where their emails are outside their own laptop or mobile phone, times have evolved greatly from when we were people punching numbers into terminals. The world itself “thinks” and transmits more data than we ever have before, so ensuring we know what is really happening, what the data needs to do, where it should go, and for those in the technology industry, what happens to it and once it’s been sent off into the air is crucial!
As the Internet-of-Things (IoT) generates more bits and bytes than grains of sand on all the beaches of the Earth, we find the pipes they travel along getting more and more congested. Old server rooms have started to repopulate with a server or two. How familiar does this sound:
“That finance app crashes when it’s run from Azure, so we got a pair of ESXi servers and run it here in the office. While we were at it, we also DFSR copied our file shares, virtualized the door-entry system, and set up the weekly burger run rota on a spreadsheet in the office!”
Bringing data and processing closer to the staff that need it improves access, reduces latency, and indeed, makes sure everyone knows whose turn it is to buy lunch if the internet connection goes down for the day.
How modern IT works at the edge
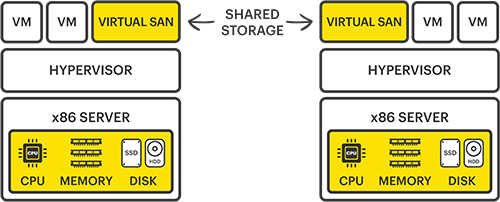
For IT at the edge, this means implementing hyperconverged solutions that combine servers, storage, and networking into a simple-to-use package. Of course, server virtualization is key to hyperconverged, but so is storage virtualization. The days of requiring externally shared physical storage are gone. Nowadays, virtual SANs have taken over, meaning that the internal server disk drives “trick” the hypervisor into thinking it still has shared access to a physical SAN to handle all its advanced functionality. Meaning there’s no need for expensive external storage anymore, as users can now use the disks they have inside the servers along with a virtual SAN software solution to provide high availability, or mirroring between nodes and ensure uptime. There are so many examples of how this approach helps solve business problems at the edge.
Wind farms generate huge amounts of data that needs processing, and only a small fraction is required to be analyzed back at the HQ. Yet, with their locations almost by definition being off the grid, how do you sift through this without some sort of machine to do it there and then? Hyperconvergence and small-footprint edge-centric devices enable the results to be transmitted at lower cost, through less bandwidth, driving overall efficiency. See how energy provider RWE achieved this in their customer story.
When you tap on that online video link, and it starts streaming to your phone, this doesn’t come from “the” Google/YouTube server, it comes from a distributed content network and cleverly optimizes the bandwidth it needs by looking at your location, analyzing the route to the closest cache and making sure that you get to see those cute puppies without clogging up bandwidth on the other side of the planet.
While these are some varied basic examples, the same is true in nearly all scenarios. This is the definition of the modern edge, and it isn’t going anywhere any time soon.
Why does edge computing matter?
To round this off, you may be asking why any of this matters to you or your organization. You may have a five-year cloud strategy and may be able to make that work and never have to reboot a server ever again. Or you may not even consider yourself edge at all. But for those in need of an alternative, having a highly available, yet simple solution that can be deployed over and over again as easily as the first, delivers the IOPs and performance required by your remote or small office branches and leverages all the technology you’ve been using for your entire career but in a way that enables the innovation, efficiency and 100% uptime we’ve all become used to instead of hindering it: you should check out StorMagic.
Related content: Five Factors to Consider for Edge Computing Deployment
Why choose StorMagic SvSAN for the edge?
A true “set and forget” solution for any environment, StorMagic SvSAN is a lightweight virtual SAN that’s simple to use and deploy. It empowers users to support, manage and control thousands of their edge sites as easily as one with centralized management, and can run on as little as 1 vCPU / 1GB RAM / 1GbE.
This powerful software is flexible – working with any hypervisor, CPU, storage combination, and x86 server – and robust – providing secured shared storage with just two nodes, and 100% high availability, even in the harshest or most remote of environments. With close partnerships with industry giants like Lenovo and HPE, SvSAN customers benefit from the freedom to deploy complete solutions if they choose, or save precious department budget with existing, or refurbished servers (read our customer case study to learn how this pharmaceutical company deployed SvSAN on refurbished servers).
For a more detailed explanation of edge computing, what it does, and how it works, dive into our edge computing beginners guide. Or if you’d like more information on StorMagic SvSAN, contact our sales team, or check out our product page here:


